
Einführung in RAG und die Bedeutung der Evaluation
Retrieval Augmented Generation (RAG) verstehen
Retrieval Augmented Generation, allgemein als RAG bekannt, stellt einen bedeutenden Fortschritt im Bereich der Künstlichen Intelligenz dar – insbesondere bei der Erweiterung der Fähigkeiten großer Sprachmodelle (LLMs) wie ChatGPT. Dieser innovative Ansatz verbindet die Leistungsfähigkeit von LLMs mit externen Wissensquellen und führt so zu präziseren und kontextuell relevanteren Antworten.
Im Kern integriert ein RAG-System drei zentrale Komponenten:
- Ein leistungsstarkes großes Sprachmodell
- Eine robuste Vektordatenbank für ein effizientes Abrufen von Informationen
- Sorgfältig gestaltete Prompts, die das Zusammenspiel zwischen dem LLM und den abgerufenen Informationen steuern
Dieses Zusammenwirken ermöglicht es RAG-Systemen, auf umfangreiche Bestände an aktuellen Informationen zuzugreifen, und verringert damit deutlich die Wahrscheinlichkeit fehlerhafter oder veralteter Antworten – eine verbreitete Herausforderung bei eigenständig arbeitenden LLMs.
Warum die Evaluation von RAG unverzichtbar ist
Da die Verbreitung von RAG-Technologien in den unterschiedlichsten Branchen rasant zunimmt, gewinnt die Bedeutung rigoroser Evaluationsmethoden zunehmend an Gewicht. Eine wirksame Evaluation von RAG-Anwendungen geht über einfache Vergleiche hinaus; sie erfordert einen umfassenden Ansatz auf Basis quantifizierbarer, reproduzierbarer und überzeugender Metriken.
Die Bedeutung einer gründlichen RAG-Evaluation lässt sich kaum überschätzen:
- Sie sichert die Präzision und Zuverlässigkeit KI-generierter Inhalte.
- Sie spielt eine entscheidende Rolle dabei, faktische Widersprüche und Halluzinationen zu minimieren.
- Sie ermöglicht die Feinabstimmung und Optimierung der verschiedenen Komponenten eines RAG-Systems.
- Sie schafft und erhält das Vertrauen der Nutzer in KI-Anwendungen.
In einer sich rasch wandelnden KI-Landschaft sind eine konsequente Evaluation und kontinuierliche Verfeinerung von RAG-Anwendungen unerlässlich, um deren Verlässlichkeit und Wirksamkeit zu wahren.
Metriken für die RAG-Evaluation
Um RAG-Anwendungen umfassend zu beurteilen, betrachten wir drei verschiedene Kategorien von Evaluationsmetriken:
- Metriken, die auf Ground-Truth-Daten aufbauen
- Metriken, die ohne Ground Truth auskommen
- Metriken auf Basis der Analyse von LLM-Antworten
Metriken auf Basis von Ground Truth
Im Kontext der RAG-Evaluation bezeichnet Ground Truth eine Menge vordefinierter, verifizierter Antworten oder relevanter Dokumentabschnitte, die bestimmten Nutzeranfragen entsprechen. Sie dienen als Referenzmaßstab, an dem sich die Leistung von RAG-Systemen messen lässt.
Wenn die Ground Truth aus vollständigen Antworten besteht, können wir Metriken wie semantische Ähnlichkeit und Antwortkorrektheit einsetzen, um RAG-generierte Antworten direkt mit der etablierten Ground Truth zu vergleichen.
Im Folgenden ein Beispiel für die Bewertung von Antworten anhand ihrer Korrektheit:
Ground Truth: Marie Curie wurde 1867 in Polen geboren. Hohe Antwortkorrektheit: Im Jahr 1867 wurde Marie Curie in Polen geboren. Geringe Antwortkorrektheit: In Frankreich wurde Marie Curie 1867 geboren.
In Fällen, in denen die Ground Truth durch Dokumentabschnitte (Chunks) repräsentiert wird, richtet sich die Evaluation auf den Retrieval-Aspekt von RAG-Systemen. Hier nutzen wir Metriken wie Exact Match (EM), Rouge-L und F1-Score, um zu beurteilen, wie wirksam das System relevante Informationen aus seiner Wissensbasis abruft und verwendet.
Ground Truth für eigene Datensätze erzeugen
Bei proprietären oder spezialisierten Datensätzen kann die Erstellung einer Ground Truth herausfordernd sein. Ein bewährter Ansatz besteht darin, leistungsstarke Sprachmodelle wie ChatGPT zu nutzen, um auf Grundlage Ihres spezifischen Datensatzes Beispielfragen und -antworten zu generieren. Darüber hinaus bieten Werkzeuge wie Ragas und LlamaIndex Funktionen, um Testdaten passgenau für Ihre individuelle Wissensbasis zu erstellen.
Metriken ohne Ground Truth
Die Evaluation von RAG-Anwendungen ohne vorhandene Ground Truth bringt besondere Herausforderungen mit sich, doch es haben sich innovative Lösungen herausgebildet, um diesem Bedarf gerecht zu werden. Ein bemerkenswerter Ansatz ist das Konzept der RAG-Triade, eingeführt vom quelloffenen Evaluationswerkzeug TruLens-Eval.
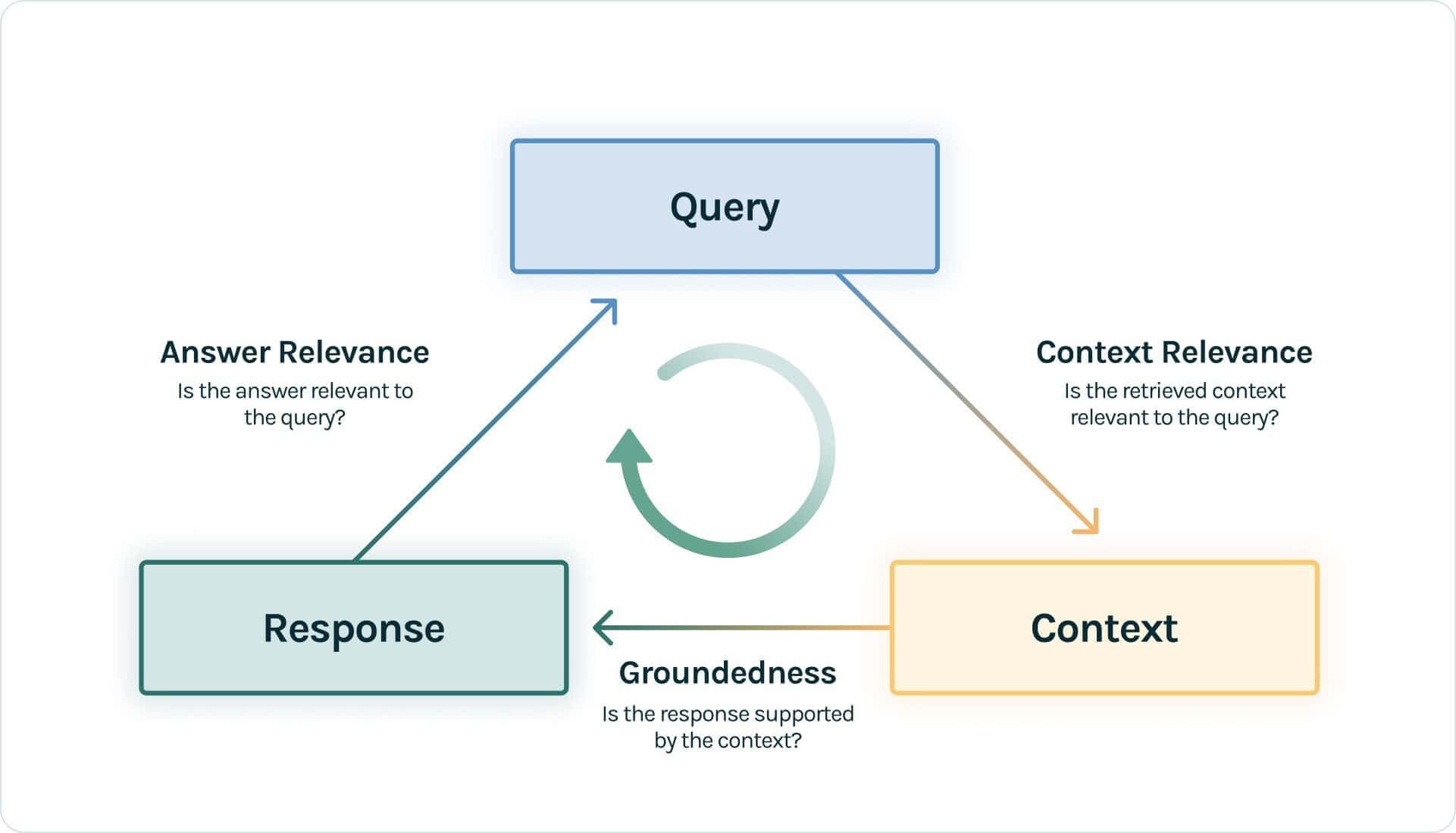
Die RAG-Triade konzentriert sich auf die Beurteilung der Wechselbeziehungen zwischen der Anfrage, dem abgerufenen Kontext und der generierten Antwort. Sie umfasst drei zentrale Metriken:
- Context Relevance: Diese Metrik bewertet, wie gut die abgerufenen Informationen zur ursprünglichen Anfrage passen und diese stützen.
- Groundedness: Sie misst, in welchem Maße die Antwort des LLM im abgerufenen Kontext verankert und durch diesen begründet ist.
- Answer Relevance: Sie beurteilt, wie direkt und angemessen die finale Antwort auf die ursprüngliche Anfrage eingeht.
Im Folgenden ein Beispiel für die Bewertung von Antworten anhand ihrer Relevanz für die Frage:
Frage: Wo liegt Japan und wie heißt seine Hauptstadt? Antwort mit geringer Relevanz: Japan liegt in Ostasien. Antwort mit hoher Relevanz: Japan liegt in Ostasien, und Tokio ist seine Hauptstadt.
Metriken auf Basis von LLM-Antworten
Die dritte Kategorie von Evaluationsmetriken konzentriert sich auf die Analyse der qualitativen Aspekte von LLM-generierten Antworten. Diese Metriken gehen über die faktische Korrektheit hinaus und beurteilen verschiedene Dimensionen der Qualität und Angemessenheit der Ausgabe.
Zu den zentralen Aspekten, die diese Metriken bewerten, zählen:
- Freundlichkeit: Wie zugänglich und nutzerfreundlich ist die Antwort?
- Schädigungspotenzial: Enthält die Antwort Inhalte, die als schädlich oder unangemessen gelten könnten?
- Prägnanz: Wie effizient vermittelt die Antwort die notwendigen Informationen?
Frameworks wie LangChain haben einen umfangreichen Satz solcher Metriken vorgeschlagen, darunter unter anderem:
- Relevanz: Wie gut geht die Antwort auf die Anfrage ein?
- Kohärenz: Ist die Antwort logisch strukturiert und leicht nachvollziehbar?
- Hilfreichkeit: Liefert die Antwort wertvolle Informationen oder Unterstützung?
- Kontroversität: Berührt die Antwort sensible oder spaltende Themen?
- Verzerrung (Bias): Lässt die Antwort unbeabsichtigte Verzerrungen erkennen?
Im Folgenden ein Beispiel für die Bewertung von Antworten anhand ihrer Prägnanz:
Frage: Wie lautet die chemische Formel für Wasser? Antwort mit geringer Prägnanz: Die chemische Formel für Wasser? Nun, das ist eine grundlegende Frage der Chemie. Die Antwort, die Sie suchen, lautet, dass Wasser aus zwei Wasserstoffatomen und einem Sauerstoffatom besteht, was als H2O dargestellt wird. Antwort mit hoher Prägnanz: H2O
Fortgeschrittene Evaluationstechniken
LLMs zur Bewertung von Metriken einsetzen
Die Bewertung von RAG-Ausgaben anhand verschiedener Metriken kann aufwendig und zeitintensiv sein. Jüngste Fortschritte bei den Fähigkeiten von LLMs eröffnen jedoch neue Möglichkeiten, diesen Prozess zu verschlanken. Mithilfe von Modellen wie GPT-4 lässt sich ein Großteil des Evaluationsprozesses durch sorgfältig gestaltete Prompts automatisieren.
Bei diesem Ansatz wird ein Prompt erstellt, der das LLM anweist, als unparteiischer Richter zu agieren und die Qualität RAG-generierter Antworten anhand bestimmter Kriterien zu bewerten. Das LLM liefert daraufhin sowohl eine qualitative Einschätzung als auch eine numerische Bewertung und ermöglicht so eine umfassende Beurteilung der Antwort.
Um möglichen Problemen vorzubeugen, sollten Sie fortgeschrittene Techniken des Prompt Engineering einsetzen, etwa:
- Multi-Shot Learning: Das Bereitstellen mehrerer Beispiele, um das Verständnis des LLM für die Aufgabe zu lenken.
- Chain-of-Thought-(CoT-)Prompting: Das Anregen des LLM, seinen Denkprozess offenzulegen, was zu transparenteren und potenziell präziseren Bewertungen führt.
Das Paper „Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena“ schlägt ein Prompt-Design für GPT-4 vor, um die Qualität der Antwort eines KI-Assistenten zu beurteilen:
[System]
Please act as an impartial judge and evaluate the quality of the response
provided by an AI assistant to the user question displayed below. Your
evaluation should consider factors such as the helpfulness, relevance,
accuracy, depth, creativity, and level of detail of the response. Begin
your evaluation by providing a short explanation. Be as objective as
possible. After providing your explanation, please rate the response on
a scale of 1 to 10 by strictly following this format: "[[rating]]",
for example: "Rating: [[5]]".
[Question]
{question}
[The Start of Assistant's Answer]
{answer}
[The End of Assistant's Answer]Wichtig ist dabei zu beachten, dass GPT-4 – wie jeder Richter – nicht unfehlbar ist und Verzerrungen sowie potenzielle Fehler aufweisen kann. Daher ist das Prompt-Design von entscheidender Bedeutung.
Halluzinationserkennung und faktische Konsistenz
Eine zentrale Herausforderung in RAG-Systemen besteht darin, die faktische Konsistenz der generierten Antworten sicherzustellen und Halluzinationen zu minimieren – also Fälle, in denen das System Informationen hervorbringt, die nicht im bereitgestellten Kontext verankert sind. Um diese Herausforderung zu adressieren, hat Vectara das Hughes Hallucination Evaluation Model (HHEM) entwickelt, das mittlerweile in seiner zweiten Version vorliegt.
HHEM v2 stellt einen bedeutenden Fortschritt bei der Halluzinationserkennung und der Bewertung faktischer Konsistenz dar. Zu seinen zentralen Merkmalen zählen:
- Mehrsprachigkeit: HHEM v2 kann Inhalte in Englisch, Deutsch und Französisch evaluieren, mit dem Plan, weitere Sprachen aufzunehmen.
- Umfangreiche Kontextverarbeitung: Das Modell kann große Textmengen verarbeiten, was es besonders für RAG-Anwendungen geeignet macht.
- Kalibrierte Bewertung: HHEM v2 liefert Werte mit einer direkten probabilistischen Interpretation. So bedeutet etwa ein Wert von 0,8 eine Wahrscheinlichkeit von 80 %, dass der evaluierte Text faktisch konsistent mit seiner Quelle ist.
| Modell | AggreFact-SOTA (Balanced Accuracy) | RAGTruth-Summarization (Precision) | RAGTruth-Summarization (Recall) |
|---|---|---|---|
| HHEM v2 | 73 % | 81,48 % | 10,78 % |
| GPT-3.5 | 56,3 % – 62,7 % | 100 % | 1,00 % |
| GPT-4 | 80 % | 46,9 % | 82,2 % |
Werkzeuge und Frameworks für die RAG-Evaluation
Nachdem wir die Evaluation einer RAG-Anwendung behandelt haben, betrachten wir nun einige Werkzeuge zur Beurteilung von RAG-Anwendungen.
Überblick über Evaluationswerkzeuge
| Werkzeug | Zentrale Merkmale | Bester Einsatzzweck |
|---|---|---|
| Ragas | Quelloffen, flexible Metriken, keine Framework-Voraussetzungen | Allgemeine RAG-Evaluation |
| LlamaIndex | In das LlamaIndex-Framework integriert, einfache Einrichtung | Evaluation LlamaIndex-basierter RAG-Anwendungen |
| TruLens-Eval | Unterstützt LangChain und LlamaIndex, visuelles Monitoring | Detaillierte Evaluation mit grafischer Oberfläche |
| Phoenix | Vollständiger Satz an LLM-Metriken, inklusive Embedding-Qualität | Umfassende LLM- und RAG-Evaluation |
Vertiefung: Ragas für die RAG-Evaluation
Ragas ist ein quelloffenes Evaluationswerkzeug zur Beurteilung von RAG-Anwendungen. Mit seiner schlichten Schnittstelle verschlankt Ragas den Evaluationsprozess. So setzen Sie Ragas ein:
from ragas import evaluate
from datasets import Dataset
dataset: Dataset
results = evaluate(dataset)
# {'ragas_score': 0.860, 'context_precision': 0.817,
# 'faithfulness': 0.892, 'answer_relevancy': 0.874}Evaluation mit Vectara integrieren
Um zu veranschaulichen, wie sich die Evaluation in einen RAG-Dienst wie Vectara integrieren lässt, betrachten wir ein Beispiel mit Ragas:
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from ragas.metrics import (
faithfulness, answer_relevancy,
answer_similarity, answer_correctness
)
def eval_rag(df):
df2 = df.copy()
df2[['answer', 'contexts']] = df2.apply(get_response, axis=1)
result = evaluate(
Dataset.from_pandas(df2),
metrics=[
faithfulness, answer_relevancy,
answer_similarity, answer_correctness
],
llm=ChatOpenAI(
model_name="gpt-4-turbo-preview",
temperature=0
),
raise_exceptions=False
)
return resultPraktische Überlegungen und bewährte Vorgehensweisen
Evaluationsdatensätze erzeugen
Eine der Herausforderungen bei der RAG-Evaluation besteht darin, geeignete Datensätze zu beschaffen oder zu erstellen. Im Folgenden einige Methoden, um dieser Herausforderung zu begegnen:
- Bestehende Benchmarks nutzen: Datensätze wie AggreFact und RAGTruth lassen sich für die allgemeine Evaluation verwenden.
- Synthetische Datengenerierung: Werkzeuge wie Ragas bieten Funktionen, um auf Basis Ihres Korpus synthetische Frage-Antwort-Paare zu erzeugen.
- Manuelle Kuratierung: Erstellen Sie einen Satz von Fragen und Antworten, die speziell auf Ihre Domäne oder Ihren Anwendungsfall zugeschnitten sind.
Hier ein Beispiel für die synthetische Datengenerierung mit Ragas:
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
gen_llm = ChatOpenAI(model="gpt-3.5-turbo")
critic_llm = ChatOpenAI(model="gpt-4-turbo-preview")
emb = OpenAIEmbeddings(model="text-embedding-3-large")
generator = TestsetGenerator.from_langchain(
generator_llm=gen_llm,
critic_llm=critic_llm,
embeddings=emb
)
testset = generator.generate_with_langchain_docs(
documents,
test_size=n_questions,
raise_exceptions=False,
with_debugging_logs=False,
distributions={
simple: 0.5,
reasoning: 0.2,
multi_context: 0.3
}
)Die RAG-Leistung optimieren
Sobald Ihre Evaluationsmetriken eingerichtet sind, besteht der nächste Schritt darin, diese Erkenntnisse zur Optimierung der Leistung Ihres RAG-Systems zu nutzen.
| Lauf | Lambda | MMR | Prompt | Faithfulness | Answer Relevancy | Answer Similarity | Answer Correctness |
|---|---|---|---|---|---|---|---|
| 1 | 0 | True | Basis | 0,9772 | 0,9427 | 0,9422 | 0,5045 |
| 2 | 0 | False | Basis | 0,9580 | 0,9395 | 0,9436 | 0,5135 |
| 3 | 0,025 | False | Basis | 0,9493 | 0,9469 | 0,9487 | 0,5640 |
| 4 | 0,025 | False | Fortgeschritten | 0,9744 | 0,9200 | 0,9550 | 0,5941 |
Wichtigste Erkenntnisse für die Optimierung:
- Experimentieren Sie mit unterschiedlichen Retrieval-Parametern (z. B. Lambda, MMR).
- Testen Sie verschiedene Prompts oder LLM-Konfigurationen.
- Beobachten Sie mehrere Metriken, um eine Verbesserung über das Gesamtbild hinweg sicherzustellen.
- Berücksichtigen Sie die Zielkonflikte zwischen verschiedenen Metriken (z. B. Faithfulness vs. Answer Relevancy).
Künftige Entwicklungen in der RAG-Evaluation
Aufkommende Herausforderungen und Lösungen
So wie sich RAG-Systeme stetig weiterentwickeln, müssen sich auch unsere Evaluationsmethoden weiterentwickeln. Im Folgenden einige aufkommende Trends und Herausforderungen in der RAG-Evaluation:
- Multimodales RAG: Sobald RAG-Systeme beginnen, Bilder, Audio und Video einzubeziehen, müssen sich die Evaluationsmetriken anpassen, um diese multimodalen Ausgaben zu beurteilen.
- Evaluation von Schlussfolgerungsfähigkeiten: Künftige RAG-Systeme könnten komplexere Schlussfolgerungen einbeziehen. Metriken zur Bewertung der Qualität und Korrektheit dieser Schlussfolgerungen werden entscheidend sein.
- Echtzeit-Evaluation: Da RAG-Systeme in Produktionsumgebungen eingesetzt werden, wächst der Bedarf an Evaluation und Monitoring in Echtzeit.
- Verzerrung und Fairness: Sicherzustellen, dass RAG-Systeme über verschiedene demografische Gruppen und Themen hinweg unverzerrt und fair sind, wird ein wichtiges Schwerpunktfeld sein.
- Effizienzmetriken: Mit wachsendem Umfang von RAG-Systemen gewinnen Metriken, die die Effizienz von Retrieval und Generierung bewerten, zunehmend an Bedeutung.
Um diese Herausforderungen zu bewältigen, ist mit folgenden Entwicklungen zu rechnen:
- Entwicklung neuer, ausgefeilterer Evaluationsmetriken
- Verstärkter Einsatz synthetischer Daten für die Evaluation
- Robustere Benchmarks, die ein breiteres Spektrum an Anwendungsfällen und Datentypen abdecken
- Integration von Evaluationswerkzeugen direkt in RAG-Frameworks für ein einfacheres Monitoring und eine leichtere Optimierung
Fazit
Die Evaluation von RAG-Anwendungen ist ein entscheidender Schritt auf dem Weg zu verlässlichen und wirksamen KI-Systemen. Durch die Kombination aus Ground-Truth-basierten Metriken, Metriken ohne Ground Truth und LLM-basierten Bewertungen lässt sich ein umfassendes Verständnis der Leistung des eigenen RAG-Systems gewinnen.
Werkzeuge wie Ragas, LlamaIndex, TruLens-Eval und Phoenix bieten leistungsstarke Möglichkeiten, um diese Evaluationen umzusetzen. Darüber hinaus eröffnen fortgeschrittene Techniken wie Vectaras HHEM v2 vielversprechende Ansätze, um anspruchsvolle Probleme wie die Halluzinationserkennung zu bewältigen.
In der sich rasch wandelnden Welt der KI ist die regelmäßige Evaluation und Verbesserung von RAG-Anwendungen entscheidend für deren Verlässlichkeit. Die hier erörterten Methoden, Metriken und Werkzeuge bieten Entwicklern und Unternehmen eine solide Grundlage, um fundierte Entscheidungen über die Leistung und die Fähigkeiten ihrer RAG-Systeme zu treffen und so den Fortschritt von KI-Anwendungen voranzutreiben.


