
Moderne RAG-Systeme haben sich gegenüber ihren frühen Formen weit entwickelt. Sie nutzen heute fortgeschrittene Verfahren, um komplexe Aufgaben der Informationsbeschaffung zu lösen. HtmlRAG etwa greift auf die ursprüngliche HTML-Struktur zurück, um sicherzustellen, dass die relevantesten Daten gefunden werden. Der Ansatz des multimodalen RAG wiederum bindet unterschiedliche Datentypen ein und verbessert so die Leistung gegenüber klassischen RAG-Modellen. Das Erfolgsrezept? Die Verbindung von Text mit visuellen Daten, wie sie multimodales RAG vorführt. Agentenbasierte RAG-Systeme (agentic RAG) bringen dagegen ein neues Maß an Autonomie mit. Sie verfeinern Suchen und passen Anfragen an und steigern damit die Treffsicherheit der Recherche. Sie fragen sich, wie agentic RAG funktioniert? Es bewertet die Qualität der Treffer kritisch und wiederholt den Vorgang für bessere Ergebnisse. Diese Innovationen definieren RAG-Systeme neu und erschließen bislang ungenutztes Potenzial in der Informationsbeschaffung.
Wichtigste Erkenntnisse
- Agentic RAG verbessert die Treffsicherheit, indem es Anfragen verändert und Suchen verfeinert.
- Multimodales RAG nutzt sowohl Text- als auch Bilddaten und übertrifft damit klassische Modelle.
- HtmlRAG verwendet die HTML-Struktur, um Dokumente intakt und relevant zu halten.
- Klassisches RAG kämpft mit der Datenqualität und mit Diskrepanzen zwischen Anfrage und Treffer.
- Künftige RAG-Systeme werden diese Grenzen überwinden und die Fähigkeiten der KI erweitern.
Klassische RAG-Systeme verstehen
Werfen wir zunächst einen Blick darauf, wie grundlegende RAG-Systeme arbeiten, um ihre Weiterentwicklung nachvollziehen zu können. Klassische RAG-Systeme verbinden einen Abrufmechanismus mit generativer KI, um die Genauigkeit der Antworten zu erhöhen. Im Mittelpunkt stehen dabei ihre Kernkomponenten, die typischen Aufbauformen und gängige Anwendungsfälle.
Klassische RAG-Systeme hängen stark davon ab, wie Dokumente verarbeitet und abgerufen werden. Sie suchen Dokumente, um KI-generierten Antworten Kontext zu geben – was mitunter zu Fehlern führt. Diese Systeme arbeiten mit Sprachmodellen zusammen, um ein Gleichgewicht zwischen Präzision und Informationsbreite zu finden.
Zu den zentralen Bausteinen gehören das Finden, Verarbeiten und Zusammenführen von Dokumenten. Abrufmechanismen setzen auf Indexierung und Suchalgorithmen, während die Verarbeitung das Parsen und Extrahieren von Kontext umfasst. Dies sind die grundlegenden Elemente klassischer RAG-Systeme, die den Weg für moderne Weiterentwicklungen geebnet haben.
Klassische RAG-Systeme beruhen oft auf einfachen Dokumentsuchen mit Schlüsselwortabgleich oder semantischer Analyse. Doch diese Methoden liefern nicht immer den gewünschten Detailgrad, gerade in spezialisierten Bereichen. Hier kommen moderne Systeme wie multimodales RAG und agentic RAG ins Spiel.
Multimodales RAG verbessert die Leistung, indem es Text und Bilder nutzt und so einen reichhaltigeren Datenkontext schafft. Es schlägt die Brücke zwischen einfachen textbasierten Systemen und der Vielfalt realer Daten. Agentic RAG verfeinert Suchanfragen und Abrufprozesse und begegnet bestehenden Grenzen, indem es die Trefferqualität durch Iteration prüft und verbessert.
Leistungskennzahlen wie Abrufgeschwindigkeit und Genauigkeit sind entscheidend für die Bewertung von RAG-Systemen. Ein hochwertiger Abruf und eine hochwertige Synthese der Daten bleiben oberste Priorität. Trotz ihrer Schwächen haben klassische RAG-Systeme die Bühne für fortschrittlichere Lösungen bereitet.
| Kernkomponenten | Abrufmechanismen | Umsetzungsmuster | Typische Szenarien |
|---|---|---|---|
| Dokumentverarbeitung | Schlüsselwortabgleich | Einfache Dokumentsuche | Kundensupport |
| Anbindung von Sprachmodellen | Semantische Analyse | Indexierung | Wissensdatenbanken |
| Daten-Parsing | Suchalgorithmen | Semantischer Abruf | Virtuelle Assistenten |
| Erzeugung von Anfrage-Antwort | Zugriff auf Indexdaten | Direkter Anfrageabgleich | FAQ-Systeme |
| Leistungskennzahlen | Schneller Abruf | Echtzeitverarbeitung | Content-Management-Systeme |
Grenzen herkömmlicher RAG-Ansätze
Betrachtet man die Grenzen typischer RAG-Methoden, zeigt sich, dass sie stark von der Qualität der abgerufenen Dokumente abhängen. Das kann bei den unterschiedlichen Typen von RAG-Systemen verschiedene Probleme verursachen. Sehen wir uns diese Grenzen genauer an:
-
Erhalt der Dokumentstruktur: Klassische Methoden haben oft Mühe, die ursprüngliche Struktur zu bewahren, wenn unterschiedliche Formate wie HTML abgerufen werden. Geht die HTML-Struktur verloren, sinkt die Qualität der Antwort.
-
Kontextverlust beim Abruf: Es besteht eine hohe Gefahr, Kontext zu verlieren – besonders bei komplexen Dokumenten. Klassische Methoden rufen mitunter Daten ab, die für sich genommen zwar relevant sind, aber nicht vollständig zur Frage des Nutzers passen.
-
Umgang mit komplexen Dokumentformaten: Der Umgang mit komplexen Formaten wie HTML oder XML ist äußerst anspruchsvoll. Diese Formate weisen häufig verschachtelte Strukturen auf, die klassische Systeme nur schwer erfassen können.
-
Grenzen bei multimodalen Inhalten: Unterschiedliche Inhaltstypen wie Text und Bilder zu kombinieren, ist schwierig. Dieses Problem wirkt sich unmittelbar auf die Leistung multimodaler RAG-Systeme aus, bei denen die Integration von Datentypen für umfassende Antworten entscheidend ist.
-
Herausforderungen beim Anfrageverständnis: Klassische Systeme missverstehen manchmal, wonach der Nutzer fragt. Das führt zu ungenauen Ergebnissen und mindert die Wirksamkeit agentic-RAG-Suchen.
-
Probleme bei Skalierbarkeit und Leistung: Große Datenmengen verlängern die Zeit bis zum Ergebnis und erschweren die Echtzeitverarbeitung. Dieses Skalierungsproblem begrenzt die Fähigkeit der Systeme, Retrieval Augmented Generation effizient durchzuführen.
-
Ressourcenbedarf und Rechenkosten: Diese Systeme benötigen viel Rechenleistung, was teuer werden kann. Den Ressourceneinsatz mit der Leistung in Einklang zu bringen, ist eine zentrale Herausforderung für Entwickler.
-
Komplexität der Integration: Die Einbindung dieser Systeme in bestehende Umgebungen kann knifflig sein. Häufig sind maßgeschneiderte Lösungen nötig, was die Abläufe verkomplizieren kann.
Diese Grenzen führten zur Entwicklung von agentic RAG und anderen fortgeschrittenen Systemen. Indem moderne RAG-Varianten wie multimodales RAG und agentic RAG diese Probleme gezielt angehen, sorgen sie dafür, dass neuere Systeme in unterschiedlichen Situationen besser abschneiden als ältere.
HtmlRAG und seine Eigenschaften erkunden

Ein Blick auf die Eigenschaften von HtmlRAG zeigt, wie es einen eigenen Weg beim Dokumentabruf geht. Indem es die HTML-Struktur nutzt, bewahrt HtmlRAG die Gliederung der Dokumente. Das ist ein deutlicher Bruch mit rein textbasierten Methoden und stellt sicher, dass der Kontext beim Abruf erhalten bleibt.
HtmlRAG hebt sich ab, weil es von der einfachen textbasierten Suche zu einem System übergegangen ist, das Struktur versteht. Dadurch verbessern sich die Qualität der Informationen und der Erhalt des Kontextes erheblich. Gegenüber der klassischen Dokumentverarbeitung bietet HtmlRAG klare Vorteile – vor allem dort, wo der Erhalt der Dokumentstruktur entscheidend ist.
Wer HtmlRAG einsetzen möchte, muss bestimmte Aspekte bedenken, etwa die Auswirkungen auf die Leistung und mögliche Zielkonflikte. So kann HtmlRAG zwar den Dokumentabruf verbessern, benötigt aber unter Umständen mehr Rechenressourcen und einen höheren Einrichtungsaufwand. Entwickler sollten diese Punkte sorgfältig abwägen, um das volle Potenzial auszuschöpfen.
Interessanterweise hat HtmlRAG neue Geschäftschancen eröffnet, weil es die Integrität der Daten wahrt. Unternehmen setzen es ein, um Content-Management-Systeme und digitale Bibliotheken zu verbessern, in denen die Dokumenthierarchie eine große Rolle spielt. Der Bedarf an Systemen, die komplexe Dokumentstrukturen ohne Datenverlust verarbeiten, war noch nie so groß.
Im Vergleich zu klassischen Abrufmethoden, die hier scheitern können, glänzt HtmlRAG beim Erhalt wesentlicher Dokumentelemente. So wird sichergestellt, dass die abgerufenen Informationen relevant und genau zugleich sind, und häufige Probleme durch unpassende Treffer werden reduziert.
Da Branchen immer ausgefeiltere Abrufmethoden benötigen, setzt HtmlRAG einen neuen Maßstab. Es harmoniert gut mit anderen fortgeschrittenen Systemen wie agentic RAG und multimodalem RAG, die den Datenabruf ebenfalls verbessern. Die Kombination dieser modernen Verfahren zeigt, wie weit sich Retrieval Augmented Generation entwickelt hat.
Kurz gesagt: HtmlRAG ist mehr als nur ein Werkzeug – es ist eine neue Denkweise. Indem es Struktur und Kontext in den Mittelpunkt stellt, verändert es, wie wir mit großen Mengen digitaler Informationen umgehen.
Grundprinzipien von HtmlRAG
Ein Blick auf die grundlegenden Konzepte von HtmlRAG offenbart seine besonderen Stärken. HtmlRAG legt den Fokus darauf, die Integrität der Dokumentstruktur zu wahren und zugleich die Abrufeffizienz zu steigern. Diese Struktur zu erhalten ist zentral, denn sie ermöglicht eine genauere Abbildung der Dokumente. Darin unterscheidet es sich von klassischen RAG-Systemen, die Dokumentdetails oft ignorieren.
-
Strukturerhalt: Die Fähigkeit von HtmlRAG, die Gliederung des Dokuments zu bewahren, macht es einzigartig. So bleibt der Kontext konsistent, was für eine genaue Datenabbildung entscheidend ist.
-
HTML-Verarbeitung: Das System ist stark darin, HTML-Details zu verstehen und zu erhalten. Das ist ein großer Vorteil bei Aufgaben, die ein präzises Dokumentverständnis erfordern.
-
Verwaltung der Dokumenthierarchie: HtmlRAG steuert die verschiedenen Ebenen eines Dokuments wirkungsvoll und sorgt dafür, dass beim Abruf nie Kontext verloren geht.
-
Kontexterhalt: Indem es den ursprünglichen Kontext bewahrt, reduziert HtmlRAG Fehler, die bei unpassenden Treffern häufig auftreten – und wird so zur verlässlichen Wahl.
-
Überblick über die Verarbeitungspipeline: Die Verarbeitungspipeline des Systems bewältigt HTML-Daten effizient und steigert die Datengeschwindigkeit, ohne die Qualität zu beeinträchtigen.
-
Anbindung an LLM-Systeme: Die nahtlose Anbindung von HtmlRAG an große Sprachmodelle (LLMs) erweitert seine Abruffähigkeiten. Diese Kombination unterstützt komplexe Anfragen mühelos.
-
Leistungsoptimierung: Dank seiner fortgeschrittenen Algorithmen ist HtmlRAG schnell und genau – unverzichtbar für den Umgang mit großen Datenmengen.
Neben HtmlRAG waren die Bemühungen um multimodale RAG-Systeme wesentlich. Diese Systeme steigern die Leistung, indem sie Text- und Bilddaten verbinden und so den Datenabruf verbessern. Ebenso stellen sich agentic-RAG-Systeme der Aufgabe, Anfragen zu verfeinern. Sie passen Anfragen adaptiv an und stellen sicher, dass Abrufaufgaben eng an den Bedürfnissen der Nutzer ausgerichtet sind. Jeder Ansatz trägt zu einem robusteren Datenabrufsystem bei.
Aufbau und Funktionsweise von HtmlRAG
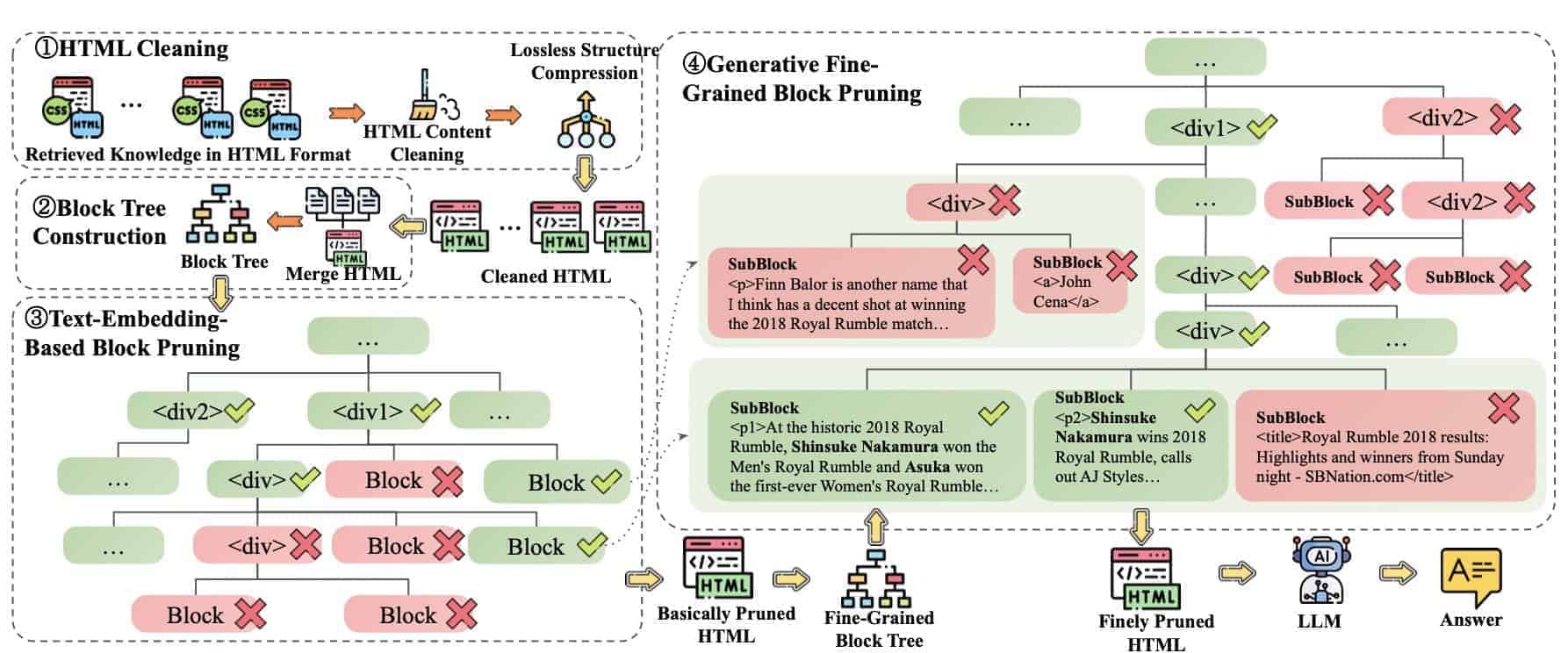
Aufbau und Abläufe von HtmlRAG geben Aufschluss darüber, wie es arbeitet. Der technische Aufbau von HtmlRAG verwaltet und verarbeitet strukturierte HTML-Inhalte wirkungsvoll und gewährleistet einen reibungslosen Inhaltsabruf. Indem es die architektonischen Komponenten in den Fokus rückt, nutzt es die HTML-Struktur, um die Datenintegrität zu sichern.
Jede Komponente spielt eine zentrale Rolle – vom Verfeinern der HTML-Elemente bis zur Steigerung der Abrufeffizienz. Dazu gehört die HTML-Bereinigung, bei der überflüssige Tags entfernt werden, um die Struktur zu vereinfachen. Pruning-Methoden verbessern dies zusätzlich, indem sie sich mithilfe eines Block-Tree-Ansatzes auf die wesentlichen Abschnitte konzentrieren. Das Ergebnis ist ein System, das sich mit größerer Genauigkeit an Nutzeranfragen anpasst und zugleich die kritischen Inhalte bewahrt.
Während Daten HtmlRAG durchlaufen, bewahren die Verarbeitungsstufen die ursprüngliche Struktur des Dokuments. Das ist entscheidend, um die Integrität des Dokuments und seine Relevanz für die Anfragen zu erhalten. Anpassungen bei der Anfrageverarbeitung steigern die Trefferrelevanz und die Abrufeffizienz und erzeugen präzisere Antworten.
Die Integration in bestehende Systeme gelingt mühelos und fördert einen reibungslosen Daten- und Abruffluss. Anschließend kommen Leistungsstrategien zum Einsatz, um eine schnelle und genaue Datenbereitstellung zu gewährleisten. Der Fokus auf die Antworterzeugung stellt sicher, dass die Informationen nicht nur abgerufen, sondern auch klar präsentiert werden.
| Komponente | Funktion | Relevanz | Schlüsselwort |
|---|---|---|---|
| HTML-Bereinigung | Vereinfacht die Struktur, entfernt überflüssige Tags | Hoch | Standard RAG |
| HTML-Pruning | Behält wesentliche Teile bei | Mittel | Types of RAG systems |
| Anfrageverarbeitung | Steigert die Trefferrelevanz | Hoch | RAG Work |
| Antworterzeugung | Sorgt für eine kohärente Informationsbereitstellung | Hoch | Agentic RAG |
| Systemintegration | Fördert einen nahtlosen Datenfluss | Mittel | Multimodal RAG |
Die detaillierte und zugleich effiziente Struktur von HtmlRAG markiert einen bedeutenden Fortschritt bei Abrufsystemen. Indem es klassische Grenzen überwindet, setzt es einen neuen Maßstab im Umgang mit HTML-Daten.
Verfahren zur HTML-Bereinigung
Das Bereinigen von HTML-Inhalten für einen besseren Abruf umfasst mehrere Methoden. Sie bereiten HTML-Dokumente auf, indem sie deren Kernstruktur bewahren und überflüssige Teile entfernen. So wird sichergestellt, dass die wesentlichen Daten für einen effizienten Abruf erhalten bleiben.
-
Ablaufschritte der HTML-Bereinigung: Beginnen Sie damit, überflüssige Tags und Attribute zu identifizieren. Sie zu entfernen kann den Inhalt verschlanken, ohne relevante Informationen zu verlieren.
-
Strategien zur Tag-Verwaltung: Nutzen Sie Regeln dafür, welche Tags behalten und welche entfernt werden, um HTML-Dateien zu optimieren. Das hilft, die Integrität des Dokuments zu wahren.
-
Methoden zur Inhaltspriorisierung: Konzentrieren Sie sich auf das, was für den Abruf nötig ist. Priorisieren Sie Text- oder Code-Abschnitte, die den Abrufkriterien entsprechen, und verwerfen Sie irrelevante Teile.
-
Ansätze zur Strukturvereinfachung: Vereinfachen Sie den Aufbau des Dokuments für eine bessere Verarbeitung. Dazu kann es gehören, verschachtelte Strukturen aufzulösen, die nicht zum Datenabruf beitragen.
-
Überlegungen zu den Leistungsauswirkungen: Beurteilen Sie, wie sich die HTML-Bereinigung auf Abrufgeschwindigkeit und Effizienz auswirkt. Ziel ist es, die Leistung zu verbessern, ohne die Datenqualität zu mindern.
-
Häufige Herausforderungen und Lösungen: Eine typische Schwierigkeit besteht darin, das Entfernen überflüssiger Daten und das Bewahren wesentlicher Informationen auszubalancieren. Ein durchdachtes Regelwerk kann dabei helfen.
-
Bewährte Vorgehensweisen und Leitlinien: Setzen Sie auf bewährte Vorgehensweisen für konsistente Ergebnisse bei der HTML-Bereinigung. Regelmäßige Überprüfungen und Aktualisierungen dieser Leitlinien halten sie wirksam.
Diese Verfahren sind entscheidend, um HTML-Dateien zu optimieren – besonders beim Einsatz moderner RAG-Systeme. Indem das HTML sauber und gut strukturiert ist, werden Abrufprozesse wirkungsvoller und weniger fehleranfällig.
Methoden des HTML-Pruning
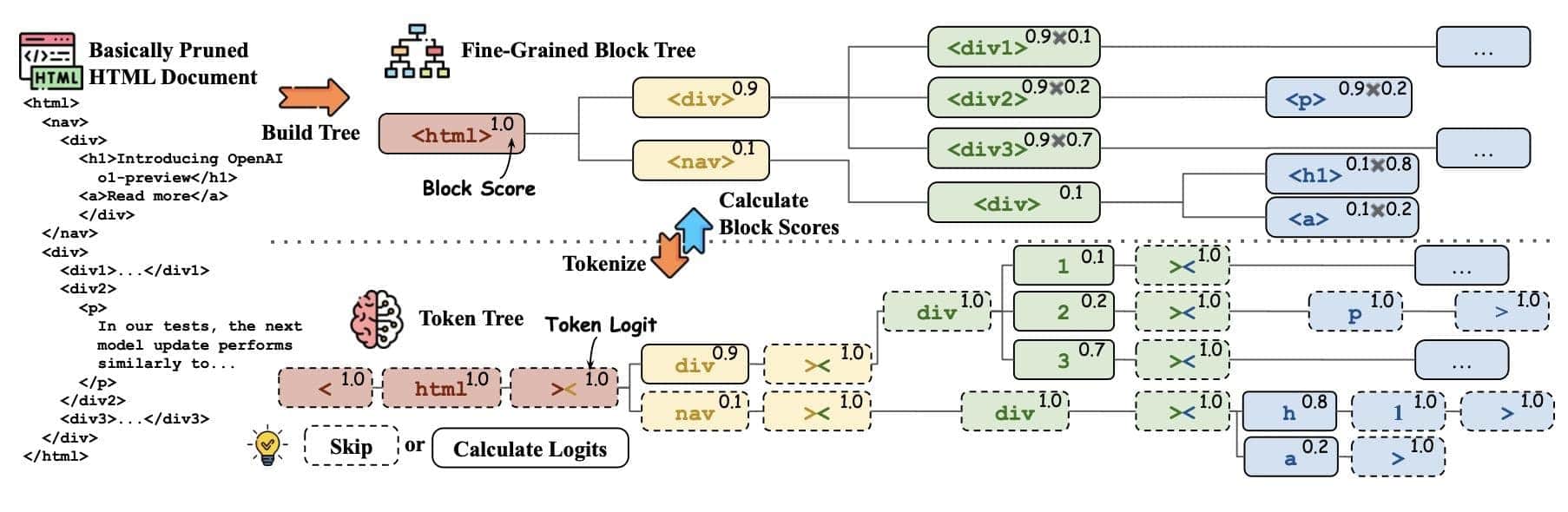
Pruning-Methoden zielen darauf ab, HTML-Inhalte durch gezielte Reduktion zu optimieren. Diese Verfahren verfeinern die Daten mithilfe von Pruning-Algorithmen. Diese Algorithmen bewerten jeden HTML-Block sorgfältig auf seine Relevanz. Sie berücksichtigen die Nutzeranfragen, priorisieren wesentliche Inhalte und entfernen Überflüssiges. Dieses Gleichgewicht zwischen Dokumentgröße und Informationsintegrität stellt sicher, dass wichtige Inhalte erhalten bleiben.
Die Leistungsoptimierung wird in diesem Schritt entscheidend. Stellen Sie sich vor, Sie suchen die Nadel im Heuhaufen – wirksames Pruning verkleinert den Heuhaufen. Es verbessert die Trefferqualität, indem es irrelevante Daten entfernt und das Dokument schlank und effizient macht.
Die praktische Umsetzung erfordert, verschiedene Faktoren sorgfältig zu bedenken. Die Entscheidungskriterien dafür, was bleibt und was entfernt wird, sollten präzise sein. Jede Entscheidung beeinflusst Abrufgeschwindigkeit und Genauigkeit. Ein gut beschnittenes HTML-Dokument beschleunigt nicht nur den Abruf, sondern stellt auch sicher, dass die abgerufenen Informationen zum Kontext passen.
Praxisanwendungen zeigen die Vorteile guten Prunings. Von schnelleren Ladezeiten bis zu besseren Suchergebnissen – die Effekte liegen auf der Hand. In Situationen, in denen multimodaler Abruf zum Einsatz kommt, sorgt Pruning dafür, dass Text gut mit visuellen Daten zusammenspielt, und verbessert so die Gesamtleistung.
In fortgeschrittenen Systemen verfeinern agentenbasierte Prozesse den Abruf weiter, indem sie Anfragen auf Grundlage erster Ergebnisse verändern. Sie passen sich an und lernen aus früheren Interaktionen, um künftige Resultate zu verbessern. Diese Anpassungsfähigkeit ist entscheidend für den Umgang mit unterschiedlichen Datentypen wie HTML und Multimedia.
Einführung in multimodales RAG

Die Entwicklung von Abrufsystemen hat interessante Fortschritte erlebt, besonders im Umgang mit unterschiedlichen Inhaltstypen. Multimodale Retrieval Augmented Generation (RAG) ist ein bahnbrechender Ansatz, der verschiedene Inhaltstypen einbezieht und die Lücke zwischen Text- und Bildinformationen schließt. Er geht über die Grenzen rein textbasierter Systeme hinaus, indem er Bilder und andere Medien in den Abrufprozess einbindet. Es ist wie ein System, das mehrere Sprachen spricht und die Details von Text und Bild gleichermaßen versteht.
Der Einsatz unterschiedlicher Modalitäten steigert Leistung und Genauigkeit und schafft ein vollständigeres Verständnis der verarbeiteten Daten. Es ist, als gäbe man einem Ermittler sowohl das Foto vom Tatort als auch die Aussage des Verdächtigen – je mehr Informationen, desto besser die Schlussfolgerung. Die Verarbeitungspipeline dieser Systeme ist fortschrittlich und zugleich effizient und ermöglicht reibungslose Übergänge zwischen verschiedenen Datentypen. Das ist entscheidend für Echtzeitanwendungen, bei denen es auf jede Sekunde ankommt.
Multimodale RAG-Systeme bewähren sich in Bereichen wie digitalem Marketing, Gesundheitswesen und Unterhaltung. Stellen Sie sich eine KI vor, die ein medizinisches Bild analysieren und mit Patientendaten abgleichen kann, um bei der Diagnose zu unterstützen. Solche Fähigkeiten zeigen das Potenzial für bessere Entscheidungen und ein besseres Nutzererlebnis. Doch es ist nicht immer einfach: Die Umsetzung dieser Systeme erfordert eine sorgfältige Auseinandersetzung mit Technologie und Datenmanagement.
Die Leistung ist von großer Bedeutung. Die Fähigkeit des Systems, große Datenmengen und komplexe Anfragen zu bewältigen, ist unverzichtbar. Hier wird es ernst – es gilt sicherzustellen, dass der Abrufprozess schnell und genau zugleich ist. Die künftige Entwicklung konzentriert sich auf noch ausgefeiltere Integrationen, möglicherweise einschließlich Echtzeit-Videoanalyse oder fortgeschrittener Bilderkennung.
Während sich diese Systeme weiterentwickeln, erweitern sich die möglichen Anwendungen und eröffnen spannende Einsatzchancen. Es geht nicht nur darum, mehr Datentypen zu nutzen, sondern darum, ein stimmiges, intelligentes System zu schaffen, das alle verfügbaren Informationen nutzt, um die besten Ergebnisse zu liefern.
Zentrale Konzepte des multimodalen RAG
Ein Blick auf die Grundprinzipien des multimodalen RAG erfordert, zu verstehen, wie diese Systeme unterschiedliche Inhaltstypen verbinden und dabei Relevanz und Kontext wahren.
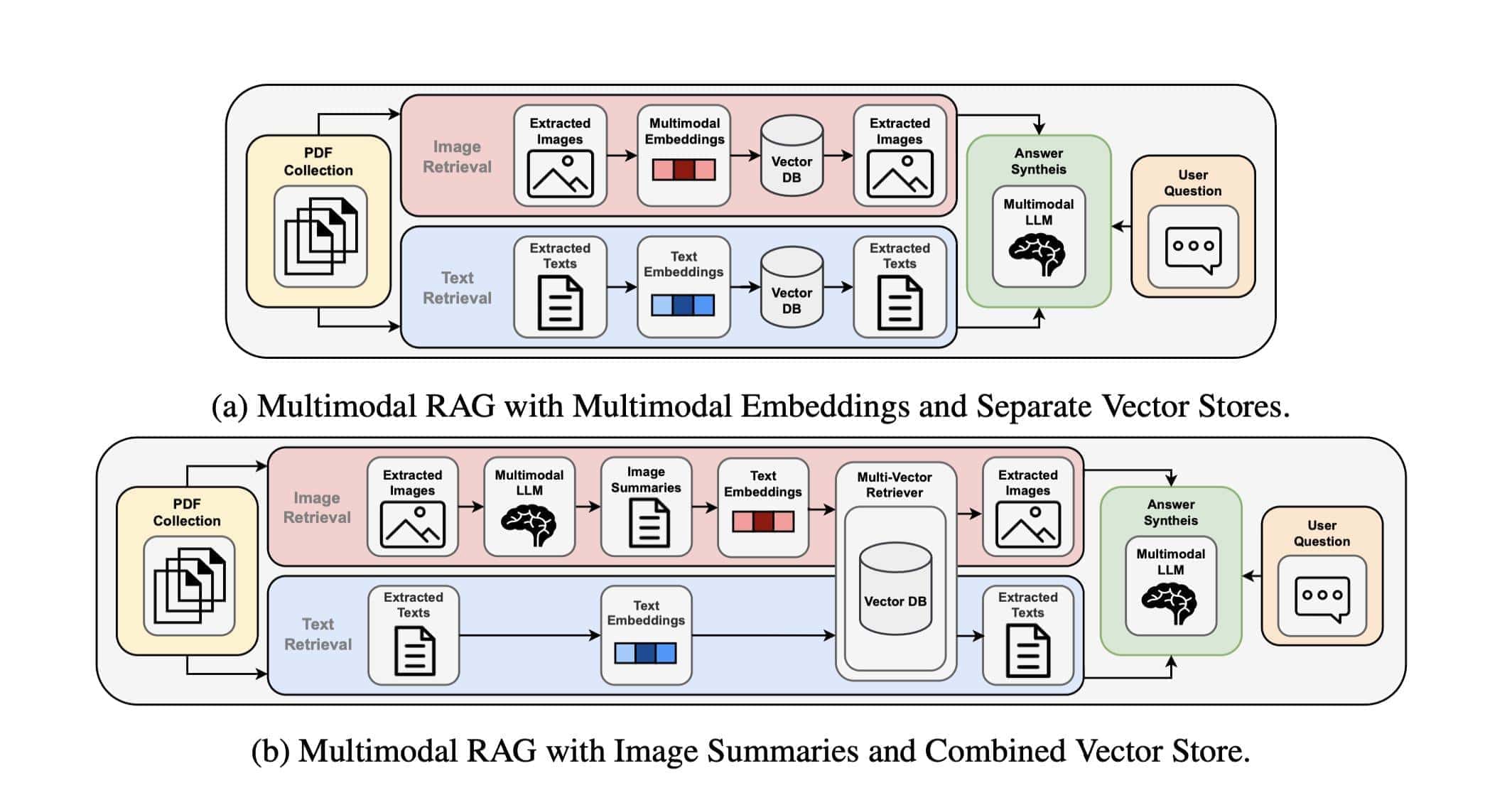 Der Prozess beginnt mit einheitlichen Embedding-Strategien, die es Text- und Bilddaten ermöglichen, reibungslos nebeneinander zu bestehen. Diese Embeddings komprimieren die Daten nicht nur, sondern stellen sicher, dass jedes Element zu einer klaren Antwort beiträgt.
Der Prozess beginnt mit einheitlichen Embedding-Strategien, die es Text- und Bilddaten ermöglichen, reibungslos nebeneinander zu bestehen. Diese Embeddings komprimieren die Daten nicht nur, sondern stellen sicher, dass jedes Element zu einer klaren Antwort beiträgt.
Auch der Umgang mit modalitätsübergreifenden Beziehungen ist entscheidend. Es genügt nicht, Text einfach mit Bildern zu kombinieren – es braucht eine sinnvolle Verbindung. Das bedeutet zu verstehen, wie sich unterschiedliche Inhaltstypen ergänzen können, um die Wirksamkeit des Gesamtsystems zu steigern.
Die Besonderheiten der Verarbeitung je Inhaltstyp betrachten, wie jeder Datentyp behandelt wird. Ob Bild oder Text – jeder Typ braucht einen eigenen Ansatz, damit nichts übersehen wird. Überlegungen zum Vektorraum sind hier wichtig und stellen sicher, dass alle Daten in einem gemeinsamen Rahmen liegen, der einen effizienten Abruf ermöglicht.
Methoden zur Relevanzbewertung sind entscheidend für hochwertige Ergebnisse. Dieser Vorgang ordnet die eingebetteten Daten und stellt sicher, dass die wichtigsten Informationen zuerst erscheinen. Verfahren zum Kontexterhalt sorgen zugleich dafür, dass die abgerufenen Daten ihre ursprüngliche Bedeutung behalten und Diskrepanzen vermieden werden.
Schließlich begegnen Integrationsherausforderungen und ihre Lösungen den Schwierigkeiten, diese unterschiedlichen Datentypen zu einem stimmigen System zu verbinden. Es ist wie das Zusammensetzen eines Puzzles, bei dem jedes Teil perfekt passen muss. Lösungen umfassen oft innovative Programmiertechniken oder die Nutzung bestehender Frameworks für eine bessere Leistung.
Leistungsanalyse multimodaler RAG-Systeme
Die Leistung multimodaler RAG-Systeme zu bewerten, erfordert einen genauen Blick auf bestimmte Kennzahlen und Methoden. Die Testmethoden konzentrieren sich auf Präzision, Recall und Antwortzeit, um ein vollständiges Bild der Systemleistung zu erhalten. Diese Kennzahlen helfen zu erkennen, wo diese Systeme glänzen und wo sie Verbesserungsbedarf haben.
Die modalitätsübergreifende Genauigkeit ist eine entscheidende Kennzahl zur Bewertung multimodaler RAG-Systeme. Sie misst, wie gut das System Informationen über verschiedene Modalitäten hinweg in Beziehung setzen und abrufen kann. Eine hohe modalitätsübergreifende Genauigkeit bedeutet, dass das System bei einer Textanfrage relevante Bilder findet – und umgekehrt.
Leistungs-Benchmarks bieten eine strukturierte Möglichkeit, verschiedene Systeme zu vergleichen, und liefern Branchenstandards als Bezugspunkte. Optimierungsstrategien konzentrieren sich auf die Feinabstimmung dieser Systeme und bringen Genauigkeit und Geschwindigkeit für das beste Nutzererlebnis in Einklang.
Auch der Ressourcenbedarf ist wichtig. Multimodale RAG-Systeme können ressourcenintensiv sein und erhebliche Rechenleistung erfordern. Die Skalierbarkeit ist eine zentrale Überlegung – das System muss seine Leistung auch dann halten, wenn die Datenmengen wachsen.
Vergleichende Studien zeigen oft, wie multimodale Ansätze textbasierte Systeme in Szenarien übertreffen, in denen visuelle Informationen erheblichen Kontext beisteuern. Diese Erkenntnisse helfen, die Stärken und die Verbesserungsbereiche dieser Systeme zu bestimmen.
Tiefer Einblick in agentic RAG

Ein genauerer Blick auf agentenbasierte Systeme der Retrieval Augmented Generation offenbart einen ausgefeilten Ansatz beim Datenabruf. Diese Systeme bringen ein neues Maß an Autonomie mit, verfeinern Suchen und passen Anfragen an, um die Treffsicherheit zu erhöhen.
Kernarchitektur von agentic RAG
Die Architektur agentic-RAG-Systeme beruht auf den Prinzipien intelligenter Agenten. Diese Agenten arbeiten autonom und treffen Entscheidungen darüber, wie sich Anfragen verfeinern und Abrufergebnisse verbessern lassen.
Die agentenbasierte Architektur führt eine Entscheidungsebene ein, die klassischen RAG-Systemen fehlt. Dazu gehören die Anfrageplanung, bei der das System strategisch entscheidet, wie es einen komplexen Informationsbedarf angeht, und die Abruforchestrierung, bei der mehrere Abrufstrategien für optimale Ergebnisse koordiniert werden.
Zu den zentralen architektonischen Komponenten zählen der Anfrageanalysator, der komplexe Anfragen in handhabbare Teilanfragen zerlegt, und der Abruf-Kritiker, der die Qualität der abgerufenen Informationen bewertet und entscheidet, ob weitere Abrufrunden nötig sind.
Mechanismen zur Selbstkorrektur
Eine der stärksten Eigenschaften von agentic RAG ist seine Fähigkeit zur Selbstkorrektur. Wenn die ersten Abrufergebnisse unzureichend oder irrelevant sind, kann das System Anfragen automatisch neu formulieren und den Vorgang wiederholen.
Diese Selbstkorrekturschleife umfasst das Abgleichen des abgerufenen Kontexts mit der ursprünglichen Anfrage, das Erkennen von Lücken oder Diskrepanzen, das Neuformulieren der Anfrage, um diese Lücken zu schließen, und das Durchführen weiterer Abrufrunden. Das Ergebnis ist ein System, das sich durch iterative Verfeinerung hochwertigen Antworten annähert.
Adaptive Anfragestrategien
Agentic-RAG-Systeme setzen adaptive Strategien ein, die sich je nach Art und Komplexität der Anfrage ändern. Bei einfachen Faktenfragen nutzt das System womöglich einen direkten Abruf. Bei komplexen, vielschichtigen Fragen zerlegt es die Anfrage unter Umständen in mehrere Teilanfragen und führt die Ergebnisse zusammen.
Diese Anpassungsfähigkeit macht agentic RAG besonders wirkungsvoll für Unternehmensanwendungen, bei denen Anfragen von einfachen Abfragen bis zu komplexen analytischen Fragen reichen. Die Fähigkeit des Systems, für jeden Anfragetyp die passende Strategie zu wählen, sorgt durchgängig für hochwertige Ergebnisse.
RAG-Systemtypen im Vergleich
Vergleicht man diese verschiedenen Typen von RAG-Systemen, wird deutlich, dass jeder seine Stärken und idealen Anwendungsfälle hat.
Klassisches RAG eignet sich nach wie vor für unkomplizierte Frage-Antwort-Aufgaben, bei denen der Dokumentbestand gut strukturiert und die Anfragen vergleichsweise einfach sind.
HtmlRAG glänzt im Umgang mit webbasierten Inhalten, bei denen die Dokumentstruktur wichtige semantische Informationen trägt. Es ist besonders wertvoll für Anwendungen, die die hierarchische Gliederung von Webseiten bewahren müssen.
Multimodales RAG ist die Wahl, wenn sich Informationen über mehrere Modalitäten erstrecken. In Bereichen wie dem Gesundheitswesen, dem E-Commerce und der Bildung, in denen visuelle und textuelle Informationen gemeinsam betrachtet werden müssen, liefern multimodale Ansätze überlegene Ergebnisse.
Agentic RAG eignet sich am besten für komplexe Anwendungen auf Unternehmensniveau, bei denen die Anfragen vielfältig sind und oft mehrere Abrufschritte erfordern. Seine selbstkorrigierende Natur macht es besonders zuverlässig für unternehmenskritische Anwendungen.
Künftige Entwicklungen im Bereich RAG

Mit Blick in die Zukunft werden sich RAG-Systeme weiter entwickeln. Wir können mit mehr hybriden Ansätzen rechnen, die die Stärken verschiedener RAG-Typen verbinden. Ein agentenbasiertes System, das multimodale Daten verarbeiten und zugleich die HTML-Struktur bewahren kann, wäre etwa ein bedeutender Fortschritt.
Weitere aufkommende Trends sind Echtzeit-RAG-Systeme, die Informationen mit minimaler Latenz verarbeiten und abrufen, personalisiertes RAG, das sich an die individuellen Vorlieben und die Historie der Nutzer anpasst, und föderierte RAG-Systeme, die Informationen über verteilte Datenquellen hinweg abrufen und dabei den Datenschutz wahren.
Das Feld der Retrieval Augmented Generation entwickelt sich rasant, und diese modernen Typen von RAG-Systemen sind erst der Anfang. Mit der weiteren Entwicklung der KI können wir noch ausgefeiltere Ansätze für die Beschaffung und Erzeugung von Informationen erwarten.


